

TH-OCR 数据录入工厂
报纸及出版物数字化的利器

【产品介绍】
北京文通公司推出的“TH-OCR 文通数据录入工厂”,是在国家“863”计划国家自然科学基金长期支持下,清华大学电子工程系智能图文信息处理研究室汉字识别研究工作的基础上开发完成的。录入工厂能够快速地将印刷的文档转化为可供阅读和可编辑的高质量电子文档,进而将电子文档应用到各类数据库、电子出版物、数字图书馆、网络资源等新型资源的建设和再版图书生产中,是行业数字信息化不可或缺的重要组成部分。
作为一家拥有自主知识产权,以清华光学字符识别TH-OCR及手写识别两大核心技术为先导的OCR技术生产商、文档影像技术和应用解决方案提供商,一直致力于文档影像技术的发展,依托清华大学强大的技术后盾,沉淀、积累了卓越的识别技术,为我国信息化建设做出了巨大的贡献。
【主要功能模块】
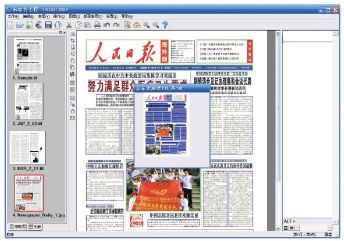
● 识别核心
TH-OCR 文通数据录入工厂内置文通公司最新研发的高性能文字识别引擎,中文识别率达99.8%以上。英文、日文、韩文的识别率居世界领先水平。
● UNICODE编码
采用UNICODE国际编码标准。系统可在一个统一的平台下,同时处理包括中文、日文、韩文、英文在内的多种文字的识别和校对修改。
● XML技术
系统基于开放式的XML数据结构,可以对数据进行扩充和再定义。支持第三方开发厂商方便地进行文档数据的转换、迁移和再利用。
● 版面还原
强大的版面还原技术,可将识别后的报刊、杂志、图书等多种形式的文档,通过还原字体、字号、版面位置、字体颜色等信息以原版原式呈现在读者面前,最终生成优质的全息PDF文档。
● 集字校对
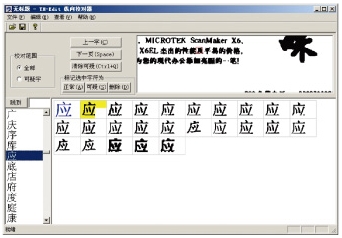
集字校对是TH-OCR 文通数据录入工厂特有的文字校对技术,该技术打破了传统校对工具图像与识别结果文本比对显示的模式,将多篇文档中所有识别结果相同的字符图像集中呈现在一个视图中,给校对人员强烈的视觉冲击,让错字自动“跳”入校对人员的眼中,避免了校对人员因陷入文档的上下文语境而产生视觉疲劳,引起的校对准确率下降。同时,由于常用汉字集中在3000-4000个左右,面对海量文字的校对时,不会因文字量的上升带来相应的校对量的上升,仍只需校对这几千个不同的汉字,明显提高工作效率。
● 增量识别
增量识别功能允许用户只识别手工编辑修改过的或新增加的区域,而保留其他已经完成校对的文字区域,为用户使用提供最大的灵活性与方便性。
● 自学习功能

针对古籍、科研等特殊领域文档中经常出现的特殊文字,即使不在国家标准范围以内或者TH-OCR字库中并没有支持,用户也可通过自学习功能,将这些文字的图像学习进入系统,使得调整后的核心可以支持这些文字的识别。
● 双层PDF批量制作功能
可以实现图像文件到PDF文件的自动转换,生成的PDF文件能够实现全文检索,可以复制粘贴,也可以对某个指定目录进行长期监视,真正实现无人操作。
【典型应用】
图书馆
中国国家图书馆 清华大学图书馆 上海交大图书馆 天津南开大学图书馆
在数字图书馆领域拥有上百家用户
电力行业
国电信息中心 各省市电力设计院 各省市电力科学院
在电力标准数字化项目中广泛应用
出版社
商务印书馆 中华书局
在古籍识别技术领域得到了客户的首肯
报杜
大连日报社 深圳特区报 南方周末
在生产流程化管理系统已成为报业信息化的首选要素
政府机关
中央办公厅 国家安全部九局 水利部 国家质量技术监督局
网络了最多的政府机关用户

扫一扫 关注我们

